
Linux, widely regarded as the most extensively used general-purpose operating system in software engineering, is renowned for its stability and robustness. However, Linux has its limitations in certain specialized work environments. In domains that demand extremely low system latency, Linux may not perform adequately.
During my time working in high-frequency trading – a sector that demands ultra-low-latency systems, I learned about numerous system tricks. While financial trading firms have significantly advanced beyond the scope of what we’ll discuss here, the solutions they’ve developed still hold relevance for others looking to enhance their system performance.
The journey of a network packet
Before we begin our discussion, let’s first take a look at how a network packet travels through a Network Interface Card (NIC), undergoes multiple operations by the operating system, and is finally received by our application.

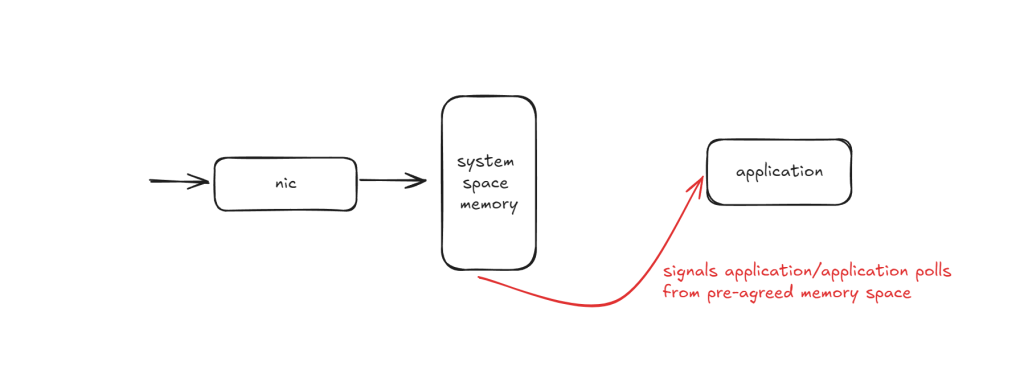
The process begins when the Network Interface Card (NIC) physically receives a data packet from the network. The packet is then directly memory accessed (DMA) to a designated area in the system memory. From there, it’s moved to the system ring buffer before being transferred to the kernel’s socket buffer.
Once the packet resides in the socket buffer, it becomes accessible to the application. A signal is issued to awaken the application, which then retrieves the packet for processing.
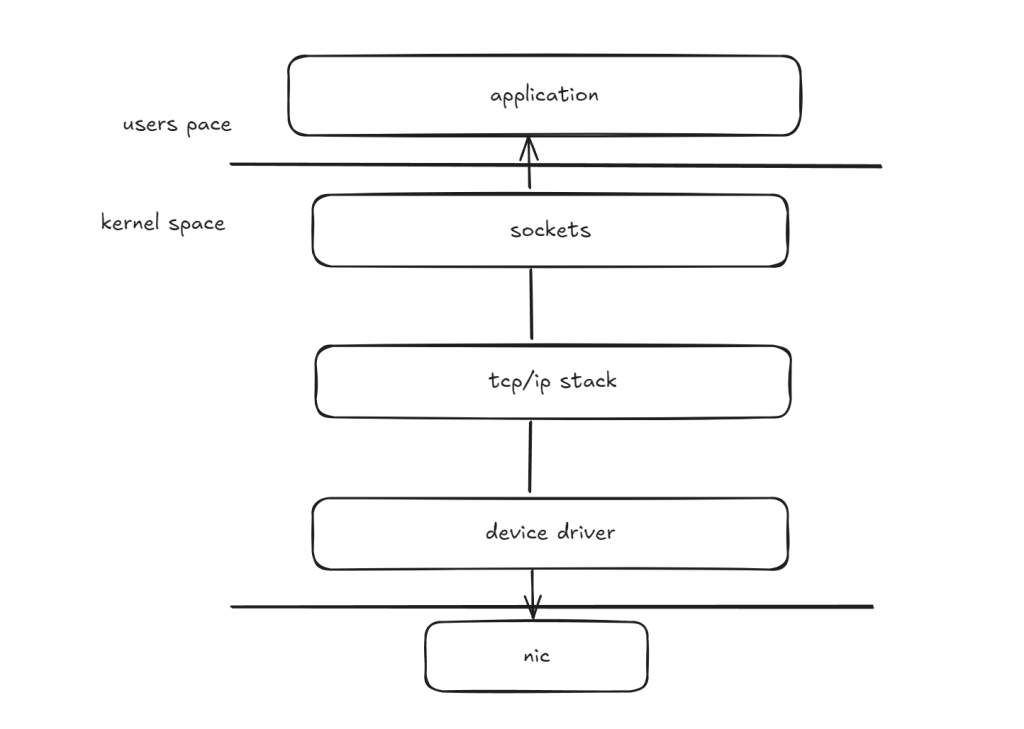
Let’s take a look from a vertical perspective. This diagram offers a general overview of how data moves through the kernel networking stack of both the host’s and the receiver’s operating systems. You can clearly see that context switching occurs when packets are transmitted to the application layer – a process that can be quite costly.
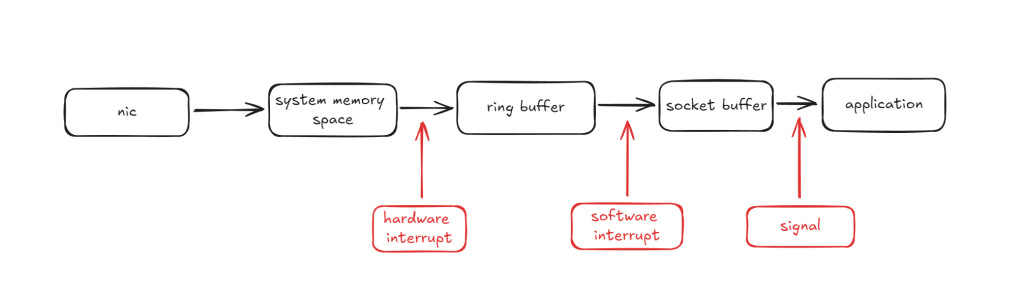
In fact, there is more than just context switching. If we zoom in a little bit into the first diagram, it’s evident that the kernel actively works to maintain system integrity, ensuring that packets are received in the correct order and that a single corrupted data bit does not compromise the entire system. Specifically, hardware and software interrupts are issued both before and after packets enter and exit the ring buffer. These steps are vital for general-purpose applications, playing a crucial role in facilitating smooth data communication within the system. However, for low-latency scenarios, these necessary system operations can become burdensome, adding unwanted delays.
Bypass interrupts
What if we could disable all interrupts, or bypass them entirely, allowing our application to directly in the userspace?
Introducing kernel bypass – a method that allows you to pass data packets into your system without involving kernel getting in the way. This idea is based off remote direct memory access (RDMA), and requires specialized hardware for it.
So how does this work?
First and foremost, the application must register a memory buffer with the RDMA hardware, or in our scenario, a specialized network device. For obvious reasons, this buffer is pinned in physical memory. Additionally, a control region is mapped into user space memory. When an application is prepared to use the buffer for sending or receiving messages, it issues a command to the control region. The hardware then transfers data from the registered buffer at one end to another registered buffer at the opposite end.
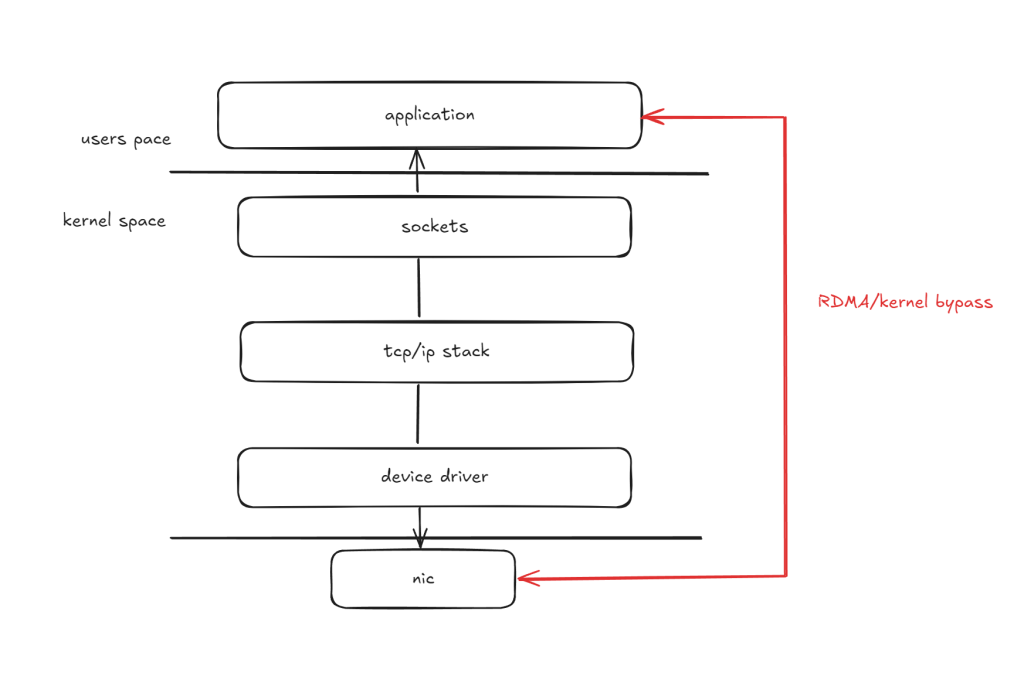
There are a range of hardware that support this type of operation. Solarflare network cards implement its kernel bypass mechanism through the usage of OpenOnload and use LD_PRELOAD to override network system calls of the target application.
Make sure critical applications have dedicated cores and are always awake
Now that we’ve successfully eliminated interrupts, what other steps can we take to further optimize system latency?
As we know, CPU cores naturally enter low-power states (C-states) when idle, and waking them up can be a costly process. In the worst case, idle caches get flushed, further slowing things down. Ideally, we want our CPU cores to stay in C-states 0 or 1 to avoid this latency.
For critical applications that demand extremely low system latency, one effective approach is to dedicate an entire CPU core and its cache to the application. This can be achieved using CPU affinity scheduling, which ensures that the application consistently runs on the same core without interruptions from other processes. Additionally, we want to avoid irrelevant kernel operations that could slow down the core. By using the nohz_full kernel parameter, we can disable scheduling clock interrupts on designated cores, preventing the kernel from interfering with real-time tasks and improving performance.
// disable scheduling clock interrupts on core 1, 6, 7 and 8
nohz_full=1,6-8
At what cost though?
Of course, these configurations come with their own trade-offs. For instance, when you eliminate hardware and software interrupts, you’re also discarding the checks and background operations that the kernel typically handles.
From a development standpoint, this shifts more responsibility to the application itself. The application now needs to directly manage hardware buffers, as previously discussed. It must handle the pushing and pulling of data packets, effectively taking over packet processing, as kernel-level features like fragmented packet handling are no longer available. Additionally, because the traffic bypasses the kernel, features such as the kernel’s routing table and network debugging tools like tcpdump are no longer functional – though you can still use alternatives like pcap.
Ultimately, while these optimizations can significantly reduce system latency, they come at a cost. By stripping away kernel assistance and increasing application-level responsibility, you increase both complexity and the risk of potential issues. Therefore, these techniques should be employed with careful consideration, especially in environments where the trade-offs between performance gains and system stability need to be balanced.

A Solarflare® SFN5162F Comparable 10Gbs Dual Open SFP network card, with OpenOnload (kernel bypass) and PXE boot support.

Leave a comment